In the summer of 2022, I had the opportunity to undertake a challenging and innovative project at Hiya, a Seattle-based company specializing in spam and robocall filtering. This project was a collaborative effort, with valuable contributions from team members Aman Singh and Marcus Chen, under the expert guidance of Tim Spillane, Damon Resnick, and Bryce Johnson.
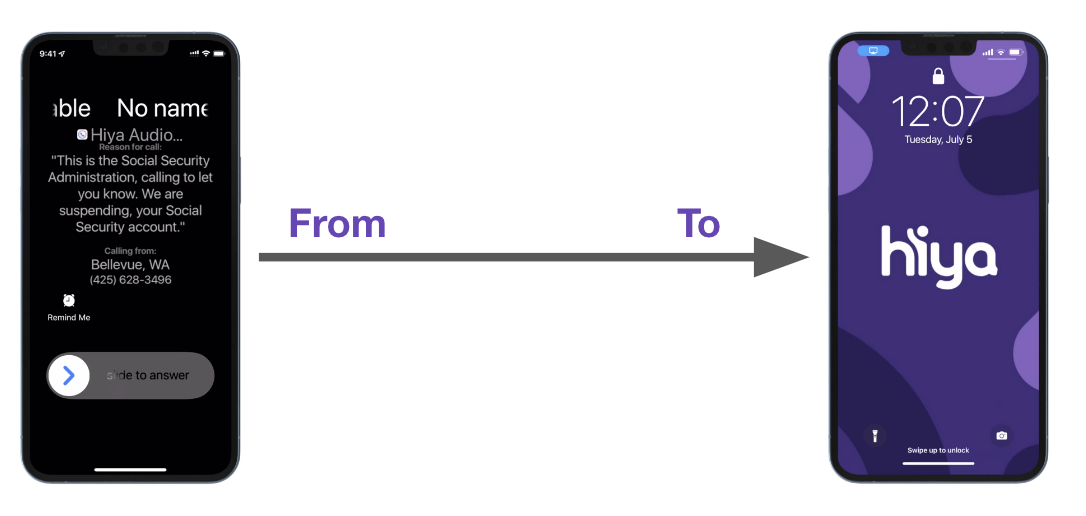
The main objective of our project was to design and implement an advanced robocall screening process in Python through AWS SageMaker. This process was aimed at identifying calls originating from a known robocall database collected by Hiya, which is referred to as a honeypot. In this context, a robocall is defined as an automated telephone call delivering a recorded message, often for political or telemarketing purposes, as outlined by Oxford Languages. It is important to distinguish these from calls made by actual individuals for promotional or sales purposes, which are subject to different regulatory treatments.
The previous product at Hiya provided call identification and transcription services to users. Our team’s innovation was the integration of Natural Language Processing (NLP) techniques to enhance this system. By implementing these techniques, we aimed to automatically identify robocalls and, upon detection, enable the system to hang up or block these calls on behalf of the user. This enhancement was designed not only to improve user experience but also to adhere to regulatory standards, ensuring that only robocalls were targeted by the blocking mechanism. Our work thus represented a significant step forward in the battle against unwanted automated calls, leveraging the power of NLP to safeguard user convenience and privacy.
Detailed Goals:
- Build a ground-truth research dataset and a honeypot library
- Investigate the differences between selected similarity metrics and pick the one with the best performance
- Quantify the relationship between audio duration and performance of robocall classification
- Find the best method that satisfy both screening accuracy and user experience
Methodology Outline
- Sample 3000+ audio from honeypot with high frequency (to avoid edge cases, e.g., robocalls from schools); Transform audio to transcripts; Conduct basic text cleanings
- Add ground-truth labels by manually listening to the audio
- Compare with honeypot library of 13,500+ files
- Adopt Sentence Transformer model pretrained on large corpus; Turn all transcripts into vector embeddings
- Investigate different similarity metrics:
- Cosine Similarity ✔️
- Euclidean Distance
- Manhattan Distance
- Jaccard Distance
- Cross-compare each sample transcript to all honeypot transcripts; Calculate cosine similarities; Decide on a “match” by setting a similarity threshold (initially 0.95) as standard
Further Research on Audio Duration
To further improve user experience (by shortening the processing time before ringing), we also investigate in the realm of audio truncation. Specifically, the system will stop listening at a chosen truncated time and start matching before the callers finish speaking. This strategy sacrifices some levels of matching accuracy but saves processing time as necessary.
In order to strike an optimal balance between accuracy and efficiency, we perform steps as follows:
- Choose truncation durations: four intervals - 10s, 15s, 20s, 25s - along with the full audio length (30s, the baseline)
- Generate new embeddings: for each truncation length within each full audio
- Only ground-truth data was truncated
- Truncated files are still compared to the full lengths files
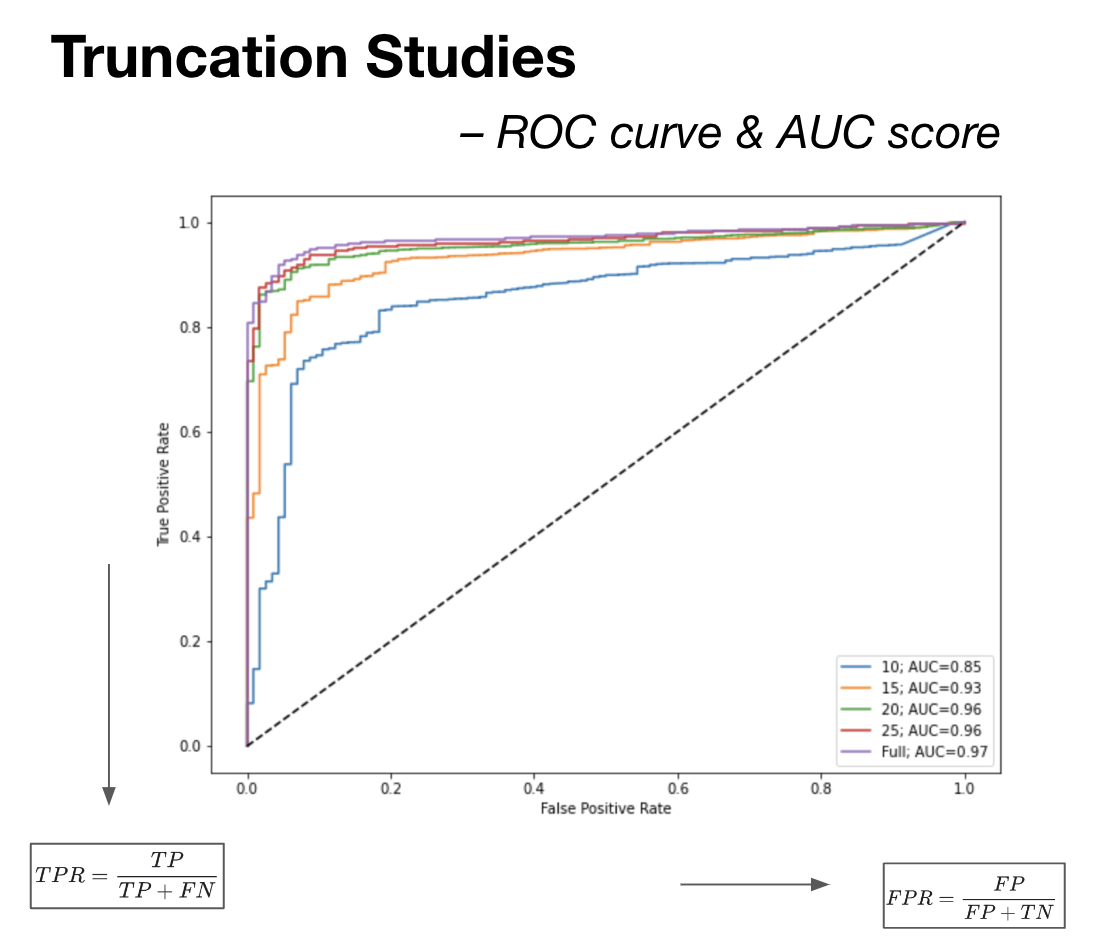
- Calculate and evaluate chosen metrics: Area Under the Curve (AUC) score, False Positive Rate (FPR), True Positive Rate (TPR), False Negative Rate (FNR)
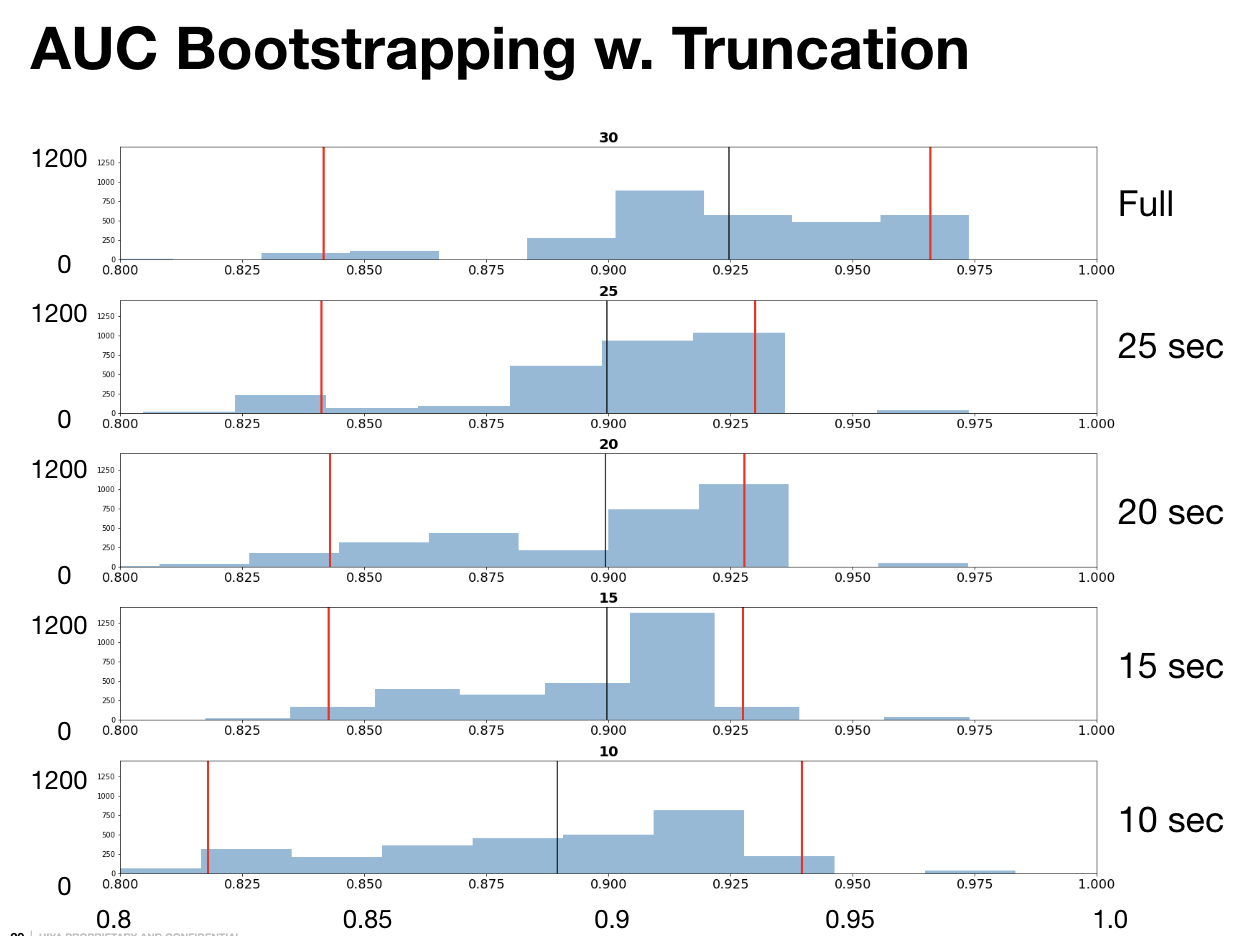
- Bootstrapping: resample new batches for the calculations of standard error, confidence interval, and hypothesis testing
- Explore optimal similarity threshold: testing different process for determining optimal threshold:
- Fixate around an acceptable FPR -> Choose the threshold yielding the lowest FNR
- Maximize TPR - FPR
- Fixate around an acceptable FPR -> Choose the threshold yielding the largest F1 score
Results
-
Highly Accurate Robocall Identification: Developed a robust NLP-based model for the matching and identification of robocalls, achieving an impressive 97% accuracy. This advanced system significantly enhanced the reliability of robocall detection, setting a high standard for automated call filtering.
-
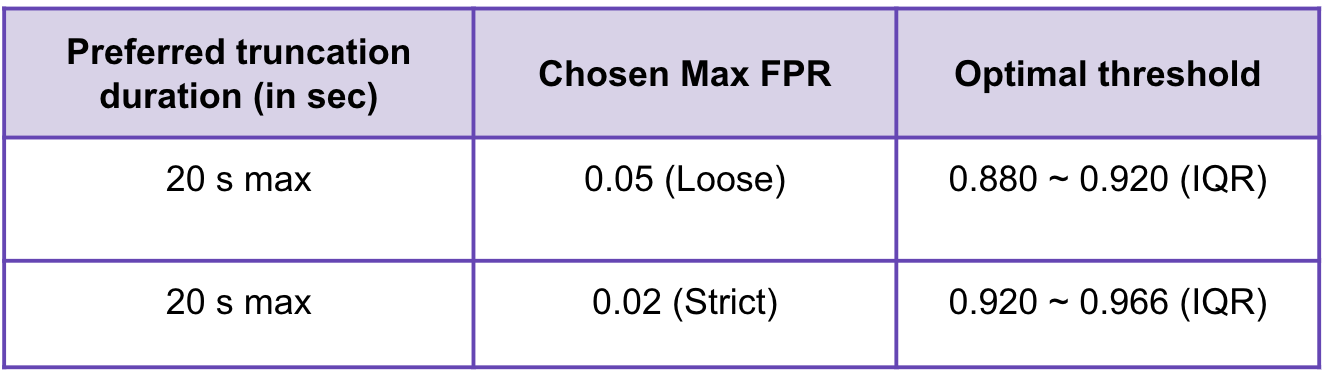
Optimized Audio Truncation for Efficiency: Strategically determined an optimal audio truncation length of 20 seconds, striking a balance between call matching efficiency and accuracy. This innovation not only maintained a high 96% accuracy rate but also markedly improved the system’s overall efficiency, streamlining the call screening process.
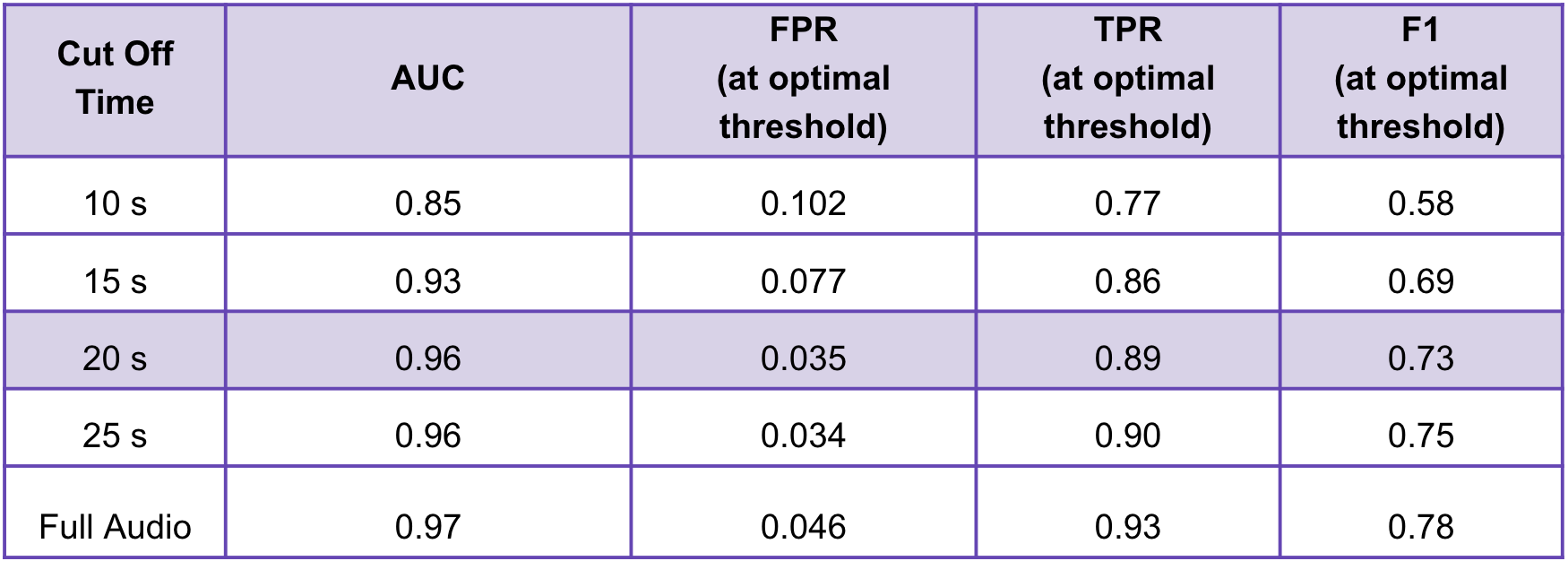
- Customizable Screening Accuracy Feature: Innovated by introducing a new, user-centric feature that allows individuals to select their desired threshold for screening accuracy within a recommended range. This feature empowers users to customize their experience based on personal preferences, offering a tailored balance between accuracy and efficiency. The introduction of this customizable screening option significantly enhanced the user experience, making the system more adaptable and user-friendly.
Documentation
In adherence to regulatory requirements, all rights to the data and source code developed during this project are retained by Hiya. For a more detailed overview and insights into our work, kindly refer to the presentation slides provided below: