| 🚩 Keywords: Rust, Cargo Lambda, Serverless Automation Function, AWS Lambda, AWS API Gateway, AWS CloudWatch | GitLab |
I recently tackled a project that elevates my efficiency in data analysis through Rust and Cargo Lambda. With Rust’s minimal runtime and control over memory layout, plus the incredible power of Cargo Lambda’s run, build, and deploy functions on AWS Lambda without containers or VMs, the project witnesses my first leap into faster large-scale data manipulation through system programming and memory considerations.
This function itself is all about piloting data manipulation and analysis with the sample data from the famous Palmer Penguins dataset. Coded in Rust and structured with Cargo Lambda, the program reads in the dataset from a CSV file, applies a filter based on a threshold value, and then calculates the mean statistics for various size variables of the penguins grouped by species. The results are neatly packaged into a JSON object format, making it easy to understand and use.
For the technical details, the project leverages several dataframe-handling crates like polars and std, which allowed me to integrate the functions I wrote in Rust into the Cargo Lambda event, including serialization and deserialization pipelines. This setup facilitates both local testing and automation in Cloud, which is pretty handy.
The file structure is straightforward, with a Cargo.lock and Cargo.toml for managing dependencies and external crates, a Makefile for shortcuts like watch, invoke, build, and deploy commands, and the source code is divided into lib.rs for data and dataframe manipulation functions, and main.rs for the Cargo Lambda pipeline. There’s also a .gitlab-ci.yml for the GitLab CI/CD pipeline setup and deployment.
Usage-wise, the program starts by reading the Palmer Penguin dataset, filtering out rows based on the body_mass_g column against a threshold value (default set to 4000). It then groups the remaining data by species and calculates the mean for other significant columns. The output is a JSON object showing the mean statistics for “tiny penguins,” based on the filter threshold. It’s a neat way to get a quick look at specific data points across different penguin species.
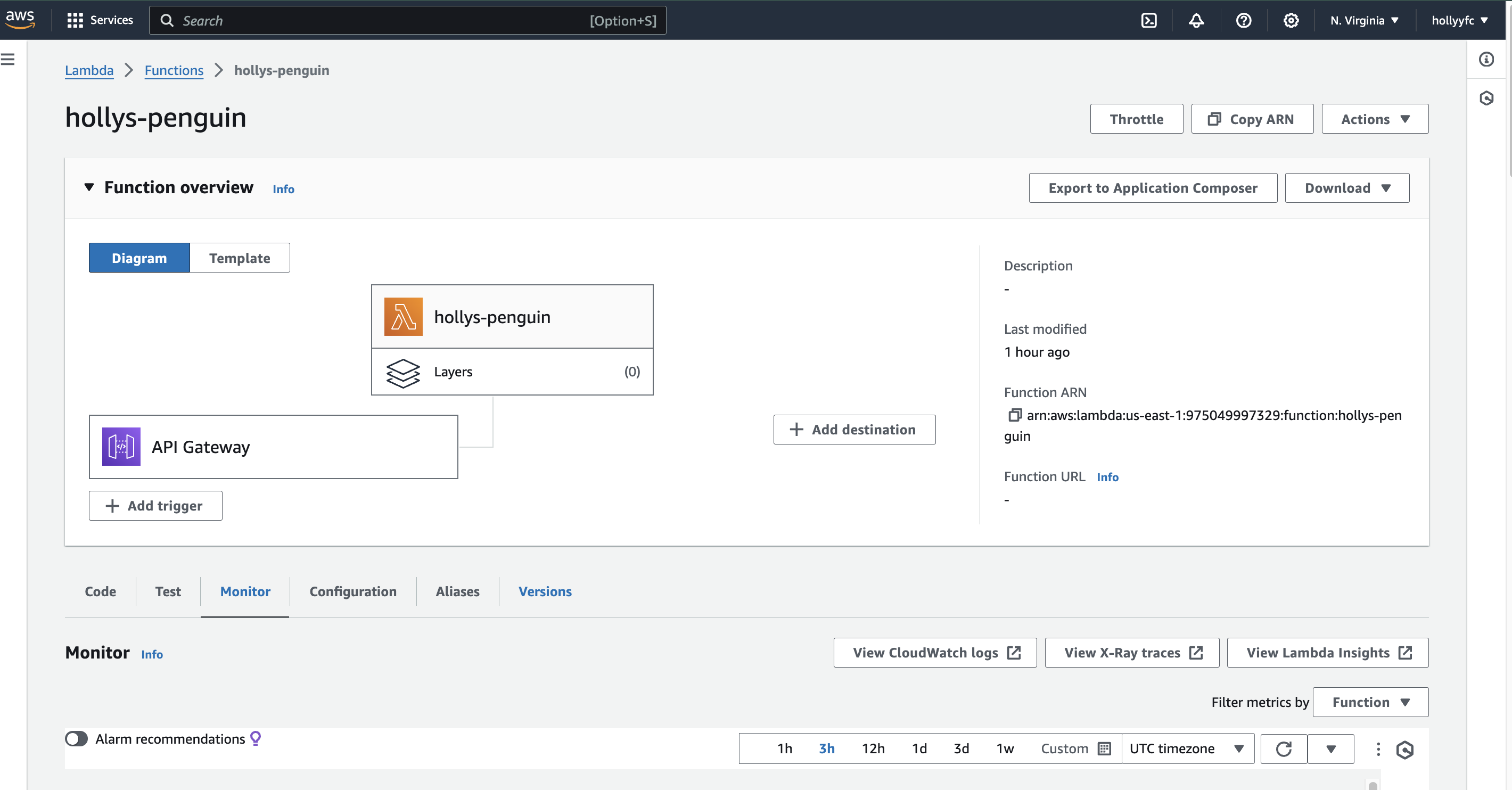
The deployment part is something I’m quite proud of. I managed to deploy the final lambda function on AWS Lambda, named hollys-penguin, and set up an API Gateway with an invoke URL. This means anyone with IAM access can now make use of this automated data analysis tool through a simple web request (either remotely or with shared cloud space). Plus, the GitLab CI/CD pipeline is in place to ensure that the project is automatically tested, built, and deployed, guaranteeing everything runs smoothly with each update.
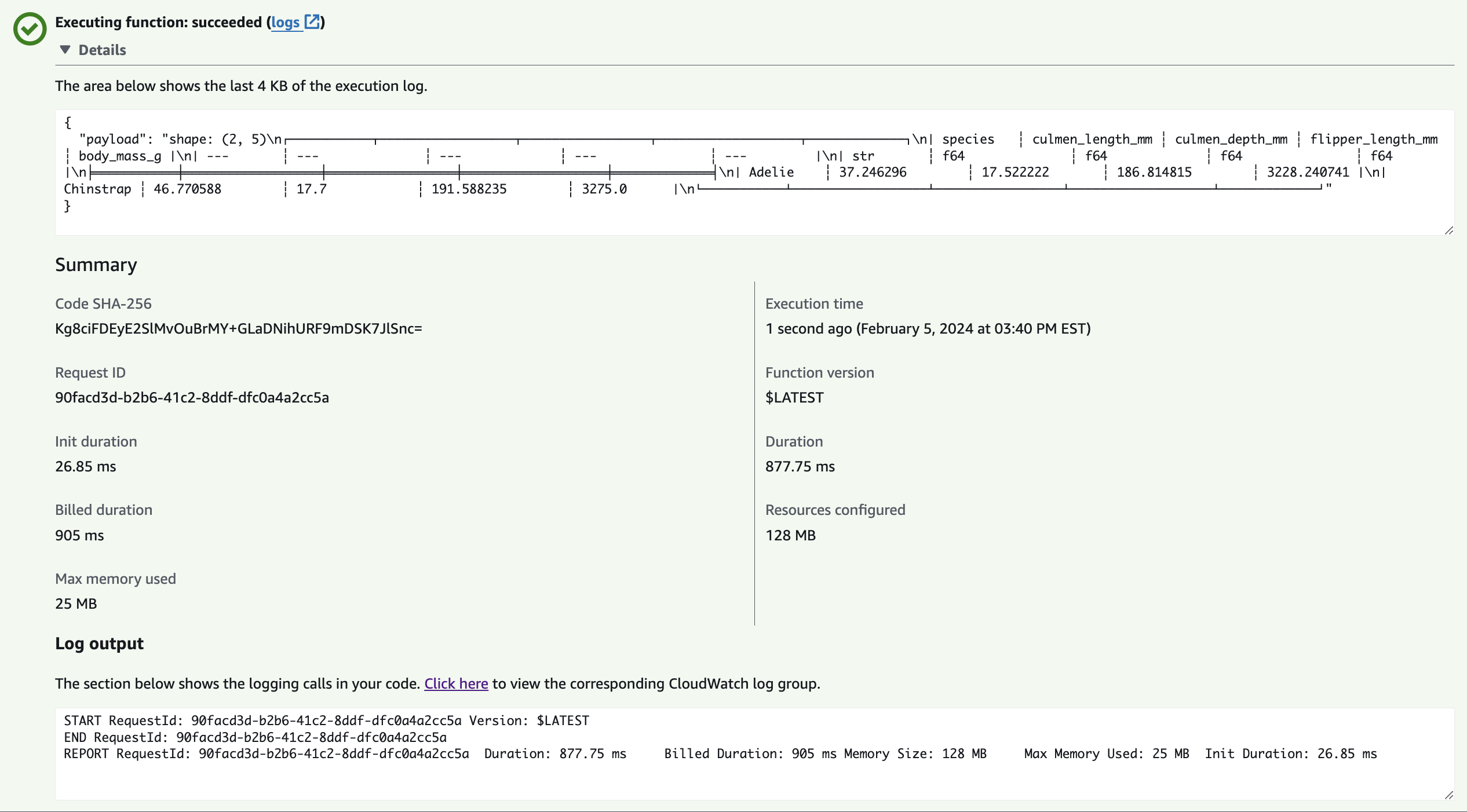
Here are some sample screenshots of the final deployment:
- AWS Lambda Setup
- Remote Test Log
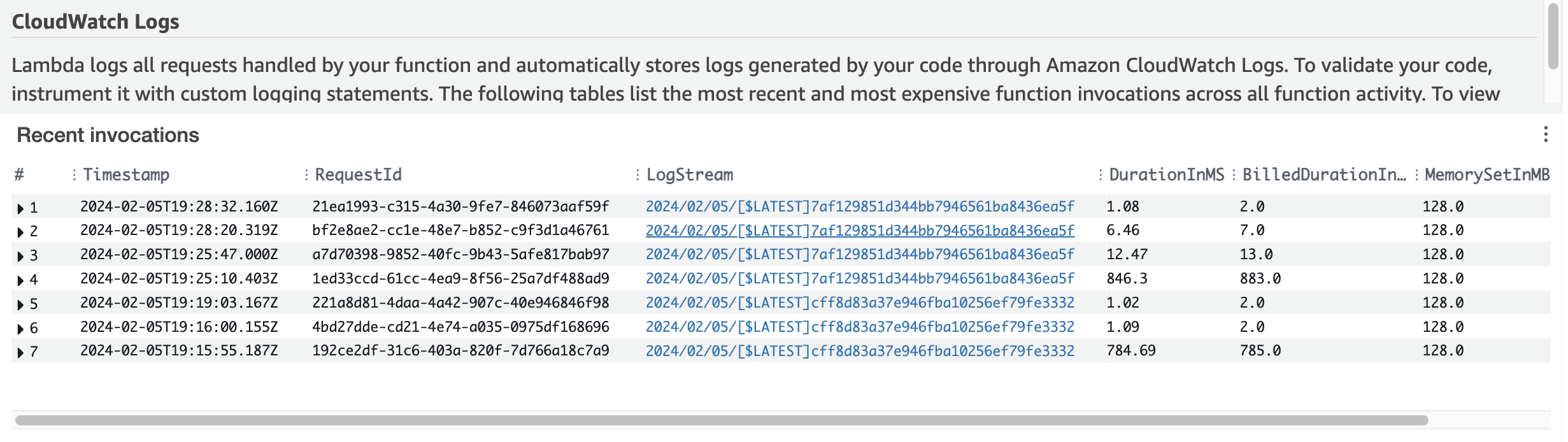
- Example Successful Test